Git 工作流
为什么要确定工作流
在使用 Git 的过程中,如果没有清晰流程和规划,每个人都提交一堆杂乱无章的 commit,那么项目很快就会变得难以协调和维护。
我们适合哪种协作方式?
每个人都直接推送到主仓库的 master 分支
在主仓库创建自己的分支进行开发,定期合并代码
将主仓库 fork 到一份个人仓库进行开发,定期提交、合并代码
常见的分支模型
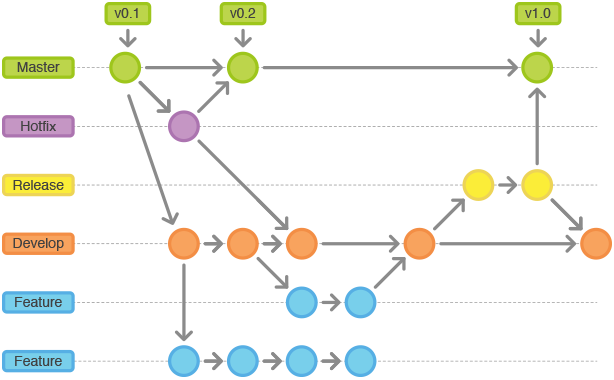
单分支模型
只创建 master 分支
生产/开发模型
支持 master、develop 类型分支
特性/发布模型
支持 master、develop、feature 类型分支
开发/发布分离模型
支持 master、develop、feature、release 类型分支
开发/发布/缺陷分离模型
支持 master、develop、feature、release、hotfix 类型分支
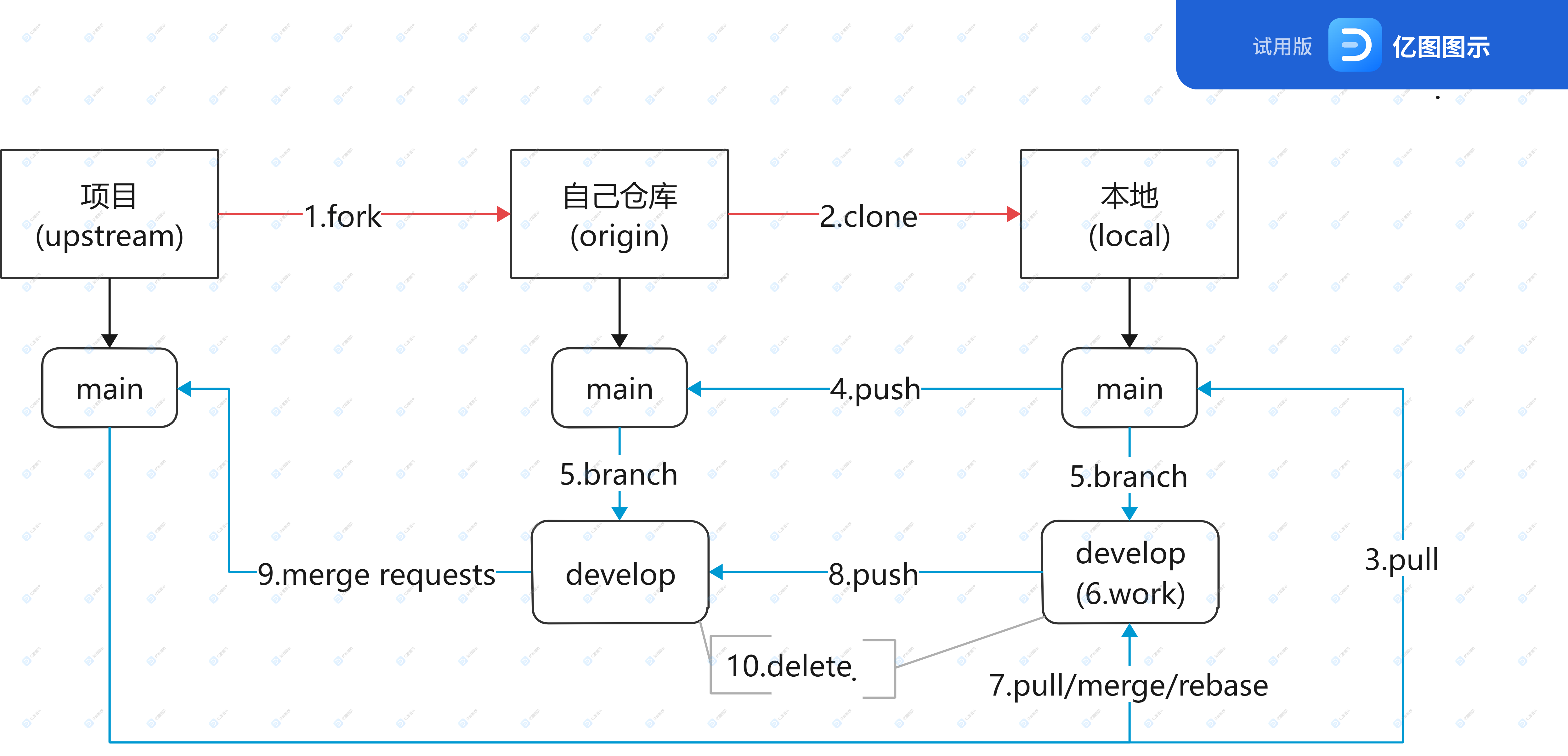
第三种workflow 流程图
 虽略显繁琐,但这样的好处是:
虽略显繁琐,但这样的好处是:
问题:对于大型项目而言,往往多人异步工作,提交信息多且协调难度大,主体项目受污染风险高。
处理:通过fork一份到个人仓库展开工作,再提交合并请求,由专人审核合并的方式可有效提高主体项目安全性,整洁度。问题:在个人仓库展开工作的过程中往往会进行多次的commit,这时发起合并请求会携带大量的臃肿的提交信息,不利于自己和审核人员的检查,审核。而且个人仓库也会变得杂乱,无用提交信息堆积。
处理:通过创建develop分支,在develop分支中展开工作,确保项目,个人仓库和本地的main同步。当develop分支完成任务后,将个人仓库的develop分支与项目的main分支进行合并,可进行提交信息的合并,降低审核人员的审核难度。且合并后删除develop,不会形成无用提交信息的堆积,保持个人仓库的整洁。
流程图说明
从项目中
fork一份到个人仓库中(gitlab/GitHub)在个人仓库中
clone到本地。在本地中,由于只关联了个人仓库(origin),缺少项目(upstream)的信息,需要进行关联:
git remote add upstream git@xxxxxxx.git
从而获取项目(upstream)。可通过 git remote -v 查看关联信息。
接着进行pull操作,拉取项目的main分支到本地的main分支,确保两者同步
git pull upstream main
项目的main分支和本地的main分支两者同步后,再进行push操作,推送本地的main分支到个人仓库的main分支中,确保 项目的main分支,个人仓库的main分支 和 本地的main分支 三者同步
在本地和项目中创建develop分支
branch,用于展开工作。(使得同步的main不受污染)。在本地的develop分支进行工作
work当在develop中完成工作后或者时间较长,项目已更新,需要进行
pull/merge/rebase操作。本地develop分支处理好后,将其
push到个人仓库的develop分支。发起
merge request,将个人仓库的develop分支,合并到项目的main分支中。根据需要合并commit信息。最后develop分支完成任务,将其删除即可。
当再次需要工作时,循环步骤3-10即可。